Can you see voice? The Brand Voice Radar.
Brand voice usually gets one page in a sixty-page brand guideline. A list of adjectives; Confident, Warm, Human, Engaging. The list barely changes from one firm to the next, and rarely changes much from one sector to the next either.
Adjectives like these are not where voice goes wrong. They’re where it starts. They’re coordinates – pointing at the territory you want a brand to occupy. The trouble begins when they’re treated as the work itself rather than the start of it.
The real work is what happens past these simple coordinates. Specific guidance, choices that turn a generic claim into a ‘way of speaking’. The patterns and constructions that distinguish one confident voice from another. Without that, the adjectives sit on the page doing nothing.
It becomes obvious when you compare voice across firms in the same sector. The adjectives recur and are interchangeable. Every firm reaches for the a handful, and most stop there. The result – a category of brands that describe themselves identically, without ever sounding like anything in particular.
That’s where the Brand Voice Radar came from.
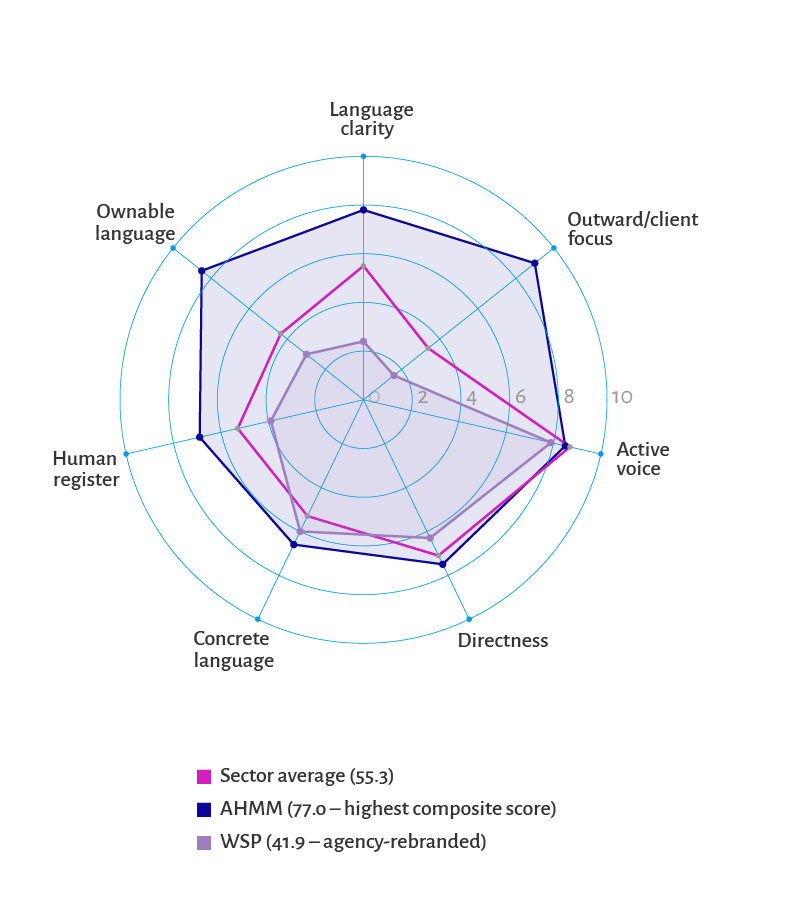
The radar measures voice across seven dimensions – language clarity, active voice, directness, concrete language, human register, outward focus, and ownable language. Each dimension is scored from a firm’s public-facing material: website, careers page, LinkedIn, reports.
The magenta shape (right) is the sector average. Lopsided, weighted toward active voice and client focus, light on ownable language and human register – the predictable shape a sector takes when most of its firms stop at the coordinates. The dark blue is the sector’s highest composite score, with a shape that’s fuller and more balanced. The weaker shape (showin in lilac) is an agency-rebranded firm, with a strong visual identity, but scoring below the sector average on almost every dimension.
The scoring isn’t arbitrary.
The buzzword lexicon at the heart of the language clarity score is derived from the sector itself: any word appearing in more than thirty per cent of firms’ copy is, by definition, category-signalling rather than ownable. The same principle shapes the rest of the radar. The criteria are built on observable patterns in the corpus, not on the analyst’s preferences.
Name-swap test
The radar applies the name-swap test as a shape. The test asks whether copy could sit on a competitor’s site without the reader noticing. Where a firm’s shape sits inside the sector average, the answer is yes – the voice is interchangeable. Where the shape pushes past, the firm has done some of the work.
The same instrument works at two scales. Across a whole sector, it shows convergence and the lopsidedness of the average. Applied to a single firm and a handful of named competitors, it produces a working diagnostic: where your voice sits, where the sector sits, and where, if anywhere, you’ve chosen something different.
This isn’t an argument against describing attributes using adjectives. They’re useful for naming what’s intended, briefing what’s wanted, agreeing what’s been delivered. But intention and execution are different things. The interesting question for any brand is not what adjectives it would use to describe itself. It’s whether those adjectives, in the public material, hold up against everyone else’s. And it's how you bring that to life.
The radar is one way to answer that.
It will not be the only way and it’s not complete. But I created it as a way to see, rather than feel, whether a voice has actually done the work past the coordinates – or whether it’s still where it usually sits, one page of seventy, looking like everyone else’s.